Gravity is in the Earth's Crust not the Core

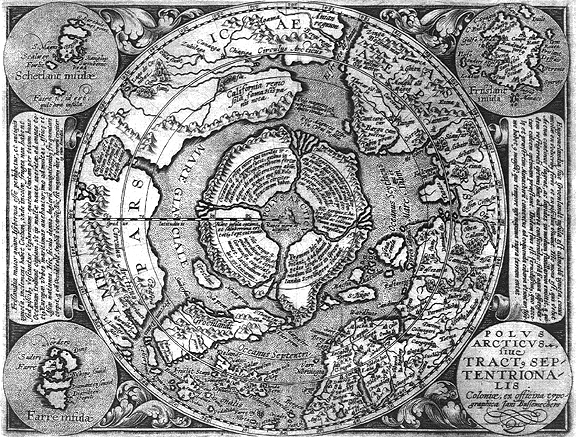
Most have difficulty visualizing how the mechanics of a hollow earth operate. Throw into the mix the idea of a hole at each pole and people really start to get confused. The best way to clear up the confusion is to realize that the earth is a hollow shell much like those eggs you poke holes in at each end and blow the yolk out of. The real clincher, however, is that gravity is centered in the Earth's crust not at its core! ... So, instead of being a point-source, the center of gravity is actually spread out at the center of the crust.
The image above helps to illustrate this point. As someone sails around the lip of the opening at the pole, you are never aware that you have just entered the inner earth opening other than a brazen solar "mirage" which is actually the inner sun. As you sail around the lip, gravity is constantly pulling towards the center of the crust so that you never notice a change in gravitational attraction. Perhaps this is why early explorers who did not have GPS made maps with a continent at the northern extremities as they did not realize that they had actually made their way to the inside of the Earth!
Advocates of mainstream science use Gaussian mathematics to argue that in a hollow earth model, all gravitational forces cancel each other out. If the Earth is indeed hollow, then gravity is a slightly more complicated (or simple) phenomenon than can be explained with Gaussian physics and the current scientific theory of gravity is in need of an overhaul.
posted by Shilo at 3:18 AM
![]()
![]()

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
5 Comments:
On The Essence And Matrix Of The Universe-Life
The following three sentences are the shortest data-based TOE…seriously. Very seriously.
The clearer the shorter
Natural Selection to Self Replication is Gravity
- Self-replication is the ultimate mode of natural selection is the essence and drive and purpose of the universe. Period.
- The pre-Big-Bang singularity is the ultimate self-replication (SR) of the cycling mass-energy universe. Period. (mother of universal SR mode…)
- Earth’s RNA nucleotides life is just one of the myriad modes of self-replication.
Dov Henis (comments from 22nd century)
http://universe-life.com/
http://universe-life.com/2012/11/14/701/
-The 20yrs development, and comprehensive data-based scientism worldview, in a succinct format.
-The Genome is a base organism evolved, and continuously modified, by the genes of its higher organism as their functional template.
- Everything in the universe derives from mass-energy duality, from the universe cycle between its two poles all-mass/all-energy.
- The Origin Of Gravitons is the ONLY thing unknown-unexplained in the Scientism Universe.
PS: Spoon feeding
The universe is a (circa 20 hillion yrs?) cyclic affair between all-mass and all-energy poles. NATURAL SELECTION of a mass format mandates energy intake because since the big-bang the resolved mass is reconverting at a constant rate from inert mass to energy, to moving mass. The mass that reconverts to energy SELF-REPLICATES to mass, in black holes, for the eventual re-singularity. The energy-to-mass SELF-REPLICATION process is GRAVITY. All this is enabled and goes on and mandated by/due to the small size and shape and inter-attraction of the gravitons that enable zero distance between them to re-form singularity.
I hope that now you understand what gravity is and why it is the monotheism of the universe…DH
In Windows 7 there is a magnifier app. Open this up, & look for a gear symbol. Click on this & then look for the top box on the left for, “color inversion”. You will need to activate this feature later. (No access, without it!)
Set this aside & then open up G.E.6 (or 7). Then go to the South Pole. Activate color inversion, & then look at this area with ANY color camera (NOT webcam) for, “AWESOME 3D, of the Lost Continent Of Lemuria”?!!
I discovered this about a year ago in a dream, & forgot about it, until a year later, did I find it again after purchasing an LG840G smartphone & checking out the camera on G.E.6 Works great on 2 megs or more!
In this area is also a HUGE Green Bird (Geoglyph?), with a wingspan of over 500 miles wide! This is sitting atop a chasm, that dips into the earth more than 300 miles deep. And the opening, at the bottom? It’s nearly 10 miles wide.
I don’t know if this is going to get to you. But, please check this out, & if you like it, please share with your viewers. It’s probably going to be the TOP STORY OF 2014. Yet most people, don’t even know it is there.....
I would like to ask a question regarding the hollow earth entrances located at the poles.
...If this is true.
And if pole shifts/flips are true.
Wouldn't that mean at times the entrance to our hollow earth would be in a much more tropical climate allowing people to come and go much easier?
THE GREAT science feat in 2013 על מהות ומקור היקום
The 2013 gravity comprehension/definition is the greatest science feat since the early 1920s.
Learn what, scientifically, natural gravity is and what evolution is.
Think of the consequences re classical science of this comprehension of gravity…
איך נברא היקום יש מאין
Origin And Nature of the Universe, the greatest science feat since the early 1920s.
New Science 2013 versus classical science
Classical Science Is Anticipated/Replaced By The 2013 Gravity Comprehension !!!
http://universe-life.com/2014/02/24/gravity/
Attn classical science hierarchy, including Darwin and Einstein…
“I hope that now you understand what gravity is and why it is the monotheism of the universe…DH”
=================================
Gravity is the natural selection of self-attraction by the elementary particles of an evolving system on their cyclic course towards the self-replication of the system. Period
( Gravitons are the elementary particles of the universe. RNA nucleotides genes and serotonin are the elementary particles of Earth life)
כח המשיכה
כח המשיכה הוא הבחירה הטבעית להיצמדות הדדית של חלקיקי היסוד של מערכת מתפתחת במהלך התפתחותה המחזורית לעבר שיכפולה. נקודה
( הגרוויטון הוא חלקיק היסוד של היקום. הגנים, הנוקלאוטידים של חומצה ריבונוקלאית והסרוטונין הם החלקיקים היסודיים של חיי כדור הארץ)
Dov Henis(comments from 22nd century)
http://universe-life.com/2013/11/14/subverting-organized-religious-science/
http://universe-life.com/2013/09/03/the-shortest-grand-unified-theory/
http://universe-life.com/2013/09/30/science-adjust-vision-concepts-beyond-aaas-trade-union-religion/
PS: Note, again:
- Classical Science Is Anticipated/Replaced By The 2013 Gravity Comprehension !!!
- Think of the consequences re classical science of this comprehension of gravity…
DH
נ.ב. הבנת מהות כח המשיכה מספקת בסיס הגיוני מפשט/צפוי/מתקן לכל מגזרי ורכיבי המדע הקלסי
יש פה אי- ניצול של הזדמנות/אפשרות של ישראל להדיח באלגנטיות מתורבתת את ארה"ב מעמדתה בעולם כמוליכה/המקבעת של עדר ה"מדענים/מדע" באמצעות האיגוד המקצועי האמריקאי הדתי, ולתפוס את עמדת ההולכה/פיתוח/הובלה של המדע 2013 החדש המשתדרג, ולהפוך את המדע האמריקאי לגרורה של המדע הישראלי. אי-ניצול זה הוא מחדל מטומטם /עלוב/מביש של ישראל....
דה
A source of gravity that originates in the crustal sheet is well thought out and postulated by Wallace Thornhill, under the umbrella of Electric Universe research. Gravity is an effect of the way that atoms (being slightly dipolar in nature due to spatial separation of the electron and proton) arrange themselves on large scales. Google for Wallace Thornhill, electric universe, electric/magnetic theory of gravity, and while you're at it you may be very intrigued by the myriad of primers that have been put out by Ben Davidson on his suspicious0bservers website.
I really do hope somebody notices this. ;)
http://www.holoscience.com/wp/electric-gravity-in-an-electric-universe/
Post a Comment
<< Home